简介
iptables 其实只是一个简称,其真正代表的是 netfilter/iptables 这个 IP 数据包过滤系统。为了简便,本文也将整套系统用 iptables 简称。iptables 是 3.5 版本的 Linux 内核集成的 IP 数据包过滤系统。当系统接入网络时,该系统有利于在 Linux 系统上更好地控制 IP 信息包和防火墙配置。此外,iptables 还可以进行 NAT 规则的管理。 上面有提到 netfilter/iptables 这个组合,这个组合中:
- netfilter 位于内核空间,是内核的一部分,由一些数据包过滤表组成,这些表包含内核用来控制数据包过滤处理的规则集;而 netfilter 又是由内核中若干 hook 组成的,程序在执行到内核 hook 处时便会执行数据包过滤的相关逻辑。
- iptables 位于用户空间,是一种工具。该工具可以很便捷地对 netfilter 所维护的表数据进行修改。从而可以很便捷地控制数据包的过滤规则。
相关概念
包过滤防火墙
包过滤防火墙在网络层截取网络数据包的包头(header),针对数据包的包头,根据事先定义好的防火墙过滤规则进行对比,根据对比结果,再执行不同的动作。 包过滤防火墙一般工作在网络层,所以也称为 “网络防火墙”,通过检查数据流中每一个数据包的源 ip 地址,目标 ip 地址,源端口,目标端口,协议类型(tcp,udp,icmp 等),状态等信息来判断是否符合规则。
NAT
NAT(Network Address Translation)网络地址转换,常用于局域网主机想与互联网服务通信时做地址转换,因为公网 IP 有限,且局域网主机访问公网必须要使用公网 IP 才可以访问到,因此使用 NAT 方法对地址做转换是一个很高效的方法。根据 NAT 使用场景不同可以将 NAT 分为 SNAT(Source Network Address Translation)和 DNAT(Destination Network Address Translation)。
- SNAT:用于局域网服务访问公网服务的场景。即将局域网发出的请求的原地址转换成 NAT 主机所拥有的公网 IP 地址,从而与公网服务进行通信。
- DNAT:用于公网请求访问局域网服务的场景。即将从公网接收到的请求的目的地址通过 NAT 规则所配置的局域网网段进行目标服务器局域网地址的转换,从而与局域网内服务通信。
举个例子,本地 Web 服务器 A 地址为 192.168.1.2,NAT 主机地址为 192.168.1.1,公网地址为 1.1.1.1;另一个局域网主机 B 地址为 172.16.1.2,NAT 主机地址为 172.16.1.1,公网地址为 1.1.1.2。此时 B 想要访问 A 的 Web 服务,B 对应的 NAT 主机会将 B 发出的请求的源地址转换成其公网地址 1.1.1.2 从而与 A 对应的 NAT 主机进行通信,这里就是 SNAT。而 A 对应的 NAT 主机收到该请求后会将该请求的目的地址转换成 Web 服务器 A 在局域网内的地址,即 192.168.1.2,从而与 Web 服务器 A 进行通信,这里就是 DNAT。
Netfilter Hooks
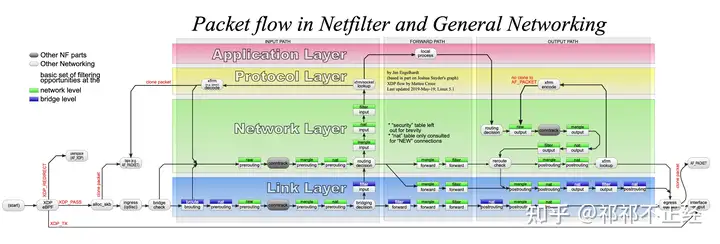
在上面的介绍中我们了解到,Netfilter 其实是内核中若干个 Hook 点组成的。数据包经过内核协议栈处理程序时,处理程序会触发 内核模块注册在相关 Hook 点上的数据包处理函数。至于处理程序会触发哪个 Hook 函数,取决于当前数据包的方向(ingress/egress)、数据包的目的地址、数据包在上一个 Hook 点的状态等等。内核中有关数据过滤的 Hook 点有如下几个:
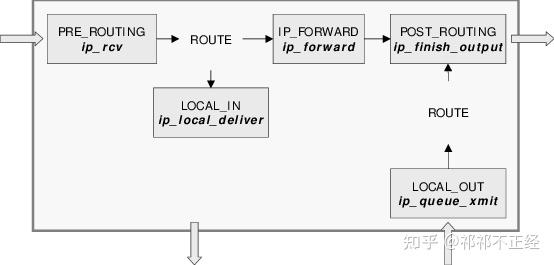
NF_IP_PRE_ROUTING:接收到的数据包进入协议栈后立即触发此 Hook,在进行任何路由判断之前NF_IP_LOCAL_IN:接收到的数据包经过了路由判断,如果目的地址是本机,将触发此 HookNF_IP_FORWARD:接收到的数据包经过了路由判断,如果目的地址是其他机器,将触发此 HookNF_IP_LOCAL_OUT:本机产生的准备发送的数据包,在进入协议栈之前立即执行该 HookNF_IP_POST_ROUTING:本机产生的准备发送的或者转发的数据包,在经过路由判断之后,将执行该 Hook
内核处理模块在往这些 Hook 上注册处理函数时,必须要提供优先级,以便 Hook 触发时能按照优先级高低 调用处理函数。这就可以保证多个内核模块(或者同一内核模块的多个实例)可以在同一个 Hook 点进行处理函数的注册,并且有确定的调用顺序。内核模块会被依次调用,并且处理完成后返回一个结果给 netfilter 框架,告诉某个数据包应该做什么操作。
表(tables)、链(chains)、规则(rules)
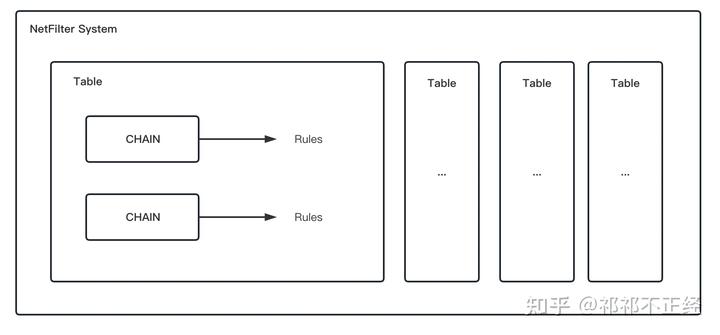
iptables 通过 表(tables)、链(chains)和 规则(rules)来管理数据包处理函数,结合对 netfilter 的了解可知,iptables 会将这些数据包处理函数注册到内核提供的五个 Hook 点上。三者相关定义如下:
- 表(tables):表将处理同一类型的数据包规则聚合在一起。内核中内置有 4 张表,分别是
raw、mangle、nat、filter。每一张表都只包含同一类型的数据包规则,比如 nat 表只包含与网络地址转换相关的规则。 - 链(chains):每一张表包含若干链,其规定了相关规则在什么时候执行。内核中内置有 5 条链,分别对应 netfilter 提供的 5 个 Hook 点。链能够让管理员在数据包传输过程中的某一个点通过相关规则控制数据包的走向。
- 规则(rules):规则存在于链中,每一条链包含若干规则。当链被调用时,数据包处理函数将按照顺序依次匹配对应链中的所有规则。每条规则都由匹配部分 + 动作部分组成,如果数据包满足匹配规则,则会执行相关动作对数据包进行处理。
总的来说,规则是最终对数据包进行处理的部分,而表和链则是提供规则在协议栈被触发的前后顺序。三者关系可以用下面的图来表示:
规则优先级
通过上面几节的介绍,我们应该了解到:数据包在进入协议栈后,触发 Hook 点注册的相关处理函数实际上对应的是表、链、规则中的链。也就是说,某一规则的触发优先级首先取决于 chain 所在的位置。其次通过包含了该 chain 类型的 table 中所对应的实际的 chain 下的规则进行规则匹配和动作执行。在这段过程中,需要注意:
- table 有优先级:由高到低排列为:raw -> mangle -> nat -> filter
- 当有多个 table 包含同一类型的 chain 时,所有的 table 都会按照上面 table 优先级被遍历,执行 table 中实际的 chain 下的规则。
尝试了解一条规则被执行的条件和顺序,这对于后面理解 netfilter 在协议栈中处理数据包的全过程有很大的帮助,一通百通。
表
提到 iptables,常常会提到 三表五链、四表五链 等的词汇。这些词汇中提到的 三表,四表 等其实指的就是 Linux 内核中内置的常见表。Linux 内核内置的表其实有五个,分别为:
- raw
- mangle
- nat(最常用)
- filter(最常用)
- security
Raw Table
iptables 提供一个有状态的防火墙,基于 netfilter 上建立了连接跟踪的特性,即 connection tracking,简称 conntrack。iptables 在处理数据包时都会依赖之前已经判断过的数据包。例如一条 NAT 记录,在第一次处理过后就会被存储在 conntrack 的哈希表中,下次有相同的数据包,则复用处理结果。 raw 表提供的功能很简单:提供且仅提供一个让数据包绕过连接跟踪的框架。
Mangle Table
mangle 表提供 修改数据包 IP 头部 的功能,例如,修改数据包的 TTL 等。此外,mangle 表中的规则还可以对数据包打一个 仅在内核内有效的标记(mark),后续对于该数据包的处理可以用到这些标记。
Nat Table
nat 表顾名思义是用来做 网络地址转换 的。当数据包进入协议栈后,nat 表中的相关规则将决定是否修改以及如何修改数据包的源 / 目标地址,从而改变数据包被路由的行为。nat 表通常用于将数据包路由到外部网络无法直接访问到的局域网络中。
应用场景:
- 企业路由或者网关主机做 SNAT,实现共享上网(通过 POSTROUTING 链)
- 做内部网络和外部网络的 IP 地址一对一映射,常用于 dmz 区域(通过 PREROUTING 链)
- 硬件防火墙映射 IP 到内部服务器
- 可以做单个端口的映射,直接将外部的 80 相关端口映射到内部 Web 服务器非 80 端口上
Filter Table
filter 表是 iptables 中最常用的表,用来 判断一个数据包是否可以通过。在防火墙领域,filter 表提供的功能通常被称为 过滤包。这个表提供了防火墙的一些常见功能。Filter 表负责的主要是和主机自身相关的数据包处理手段,是真正负责主机防火墙功能的一张表。
Security Table
security 表的作用是 给数据包打上 SELinux 标记。SELinux 以及可以解读 SELinux 安全上下文的系统在处理由 security 表做了标记的数据包时,行为会相应做出改变。
链
内核中内置的链有且仅有 5 条。不难发现,这与前面提到的 NetFilter 提供的 5 个 Hook 点的数量是一致的。没错,内核中内置的 5 条链正是对应 5 个 Hook 点。即:
PREROUTING: 由NF_IP_PRE_ROUTINGhook 触发INPUT: 由NF_IP_LOCAL_INhook 触发FORWARD: 由NF_IP_FORWARDhook 触发OUTPUT: 由NF_IP_LOCAL_OUThook 触发POSTROUTING: 由NF_IP_POST_ROUTINGhook 触发
前面也提到过,链是位于表中的,内核内置表与内置链之间的包含关系如下表所示:
| Tables | PREROUTING | INPUT | FORWARD | OUTPUT | POSTROUTING |
|---|---|---|---|---|---|
| raw | ✅ | ✅ | |||
| mangle | ✅ | ✅ | ✅ | ✅ | ✅ |
| nat | ✅ | ✅ | ✅ | ||
| filter | ✅ | ✅ | ✅ | ||
| security | ✅ | ✅ | ✅ |
在
iptables中,nat表中的默认链包括PREROUTING、POSTROUTING和OUTPUT三个链。但是,从Linux kernel 3.7开始,新增了一个可选的INPUT链,通过引入这条链,可以更好地控制流经 NAT 系统的数据包。通常情况下,
nat表中的PREROUTING链用于处理从网络接口进入 Linux 主机的数据包,POSTROUTING链用于处理从 Linux 主机出去的数据包,而OUTPUT链用于处理本地生成的数据包。当然,在一些复杂的场景下,需要在本地主机上进行 DNAT(目标地址转换)或 SNAT(源地址转换),通过添加
INPUT链规则,就能够方便地对从外部网络流入主机的数据包进行 DNAT 访问控制。因此,虽然
nat表的默认链只有PREROUTING、POSTROUTING和OUTPUT三条链,但如果根据实际需要,也可以为nat表添加INPUT链。
这里我们对最常用的两个表:filter 和 nat 进行相关链的说明,来看看某条链在某个表中起到什么作用。
Filter Table
filter 表中有三条链:input、forward 和 output。
- input:用来过滤进入主机的数据包
- forward:负责转发流经主机的数据包,起到转发的作用,和 NAT 关系很大。想要主机支持转发需要设置内核参数
net.ipv4.ip_forward = 1 - output:用来处理从主机发出去的数据包
Nat Table
nat 表中有三条链:prerouting,postrouting 和 output。
- prerouting:在数据包到达 netfilter 系统时,在进行路由判断之前执行该链上的规则,作用是改变数据包的目的地址、目的端口等,起到 DNAT 的作用;
- postrouting:数据包发出时,当数据包经过了路由判断后执行该链上的规则,作用是改变数据包的源地址、源端口等,起到 SNAT 的作用;
- output:用来处理从主机发出去的数据包。
规则
规则是最终影响数据包的地方,一条有效的规则必须由 匹配规则 + 动作目标 组成:
- 匹配规则:提供了需要执行对应动作的目标匹配机制。通常可以匹配协议类型、目的地址、源地址、目的端口、源端口、目的网段、源网段、接收数据包的网卡、发送数据包的网卡、协议头、连接状态等。
- 动作目标:又称为 Target。是数据包满足匹配规则时触发的相应的动作。Target 分为两种类型:终止目标和非终止目标。
终止目标
Linux 内核提供如下的终止目标动作:
| 动作 | |
|---|---|
| ACCEPT | 允许数据包通过 |
| DROP | 直接丢弃数据包,不给任何回应信息,这时候客户端会感觉自己的请求没有响应,过了超时时间才会有反应。 |
| REJECT | 拒绝数据包通过,必要时会给数据发送端一个响应的信息,客户端刚请求就会收到拒绝的信息 |
| SNAT | 源地址转换,解决内网用户用同一个公网地址上网的问题 |
| MASQUERADE | 是 SNAT 的一种特殊形式,适用于动态的、临时会变的 ip 上 |
| DNAT | 目标地址转换 |
| REDIRECT | 在本机做端口映射 |
| LOG | 在 / var/log/messages 文件中记录日志信息(其实就是写入系统日志,通过 dmesg 也可以看到),然后将数据包传递给下一条规则,也就是说除了记录以外不对数据包做任何其他操作,仍然让下一条规则去匹配 |
特殊的非终止目标 —— Jumping Target
我们知道,Linux 内核内置的链只有 5 条,且这 5 条链是 netfilter hooks 触发的唯一方式。那如果我想在不影响其他链的情况下使用自己定义的链,该如何操作呢?这时就可以在内置链上配置一个 Jumping Target。实际上这里指定的就是我自定义的链的名字。例如下面的配置:
|
|
上面的配置中,INPUT 链的 target 为一条自定义的名为 KUBE-FIREWALL 的链,这样,从 INPUT 入口进入的数据包将会沿着链到达 KUBE-FIREWALL 链,然后将所有带有 0x8000/0x8000 标记的包丢弃。
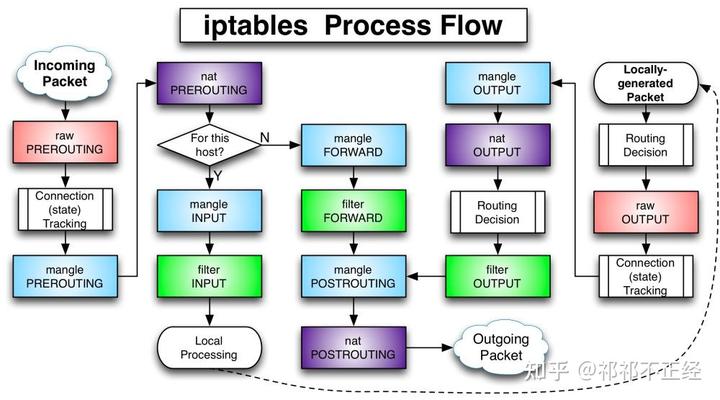
数据包处理流程图
先通过一个简单的图示来了解各个表和链在数据包处理流程上起作用的位置和效果。如下图所示,将最常用的两张表 filter 和 nat 考虑到数据包过滤流程上。
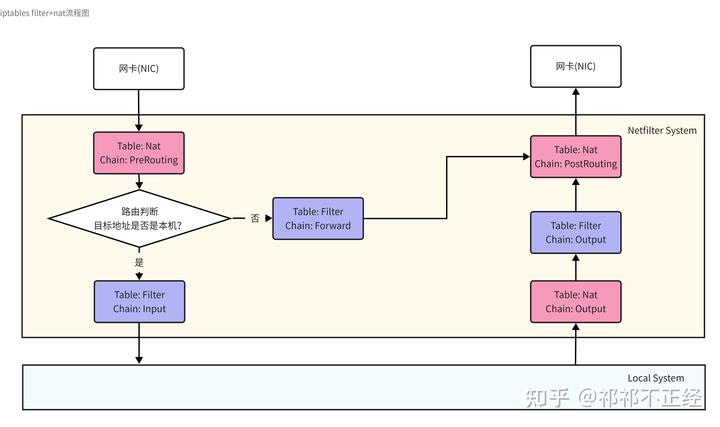
数据流入
- 当数据包流入网卡进入 netfliter 系统中时,首先对数据包进行 DNAT,将公网地址转换成局域网地址;
- 进行路由判断:
- 如果目的地址为本机地址,则进行包过滤;
- 如果目的地址不为本机地址,则准备进行包转发,经过 filter 表中 forward 链的规则匹配后,如果允许对目的地址进行转发,则进行包转发;
- 通过 Nat 表中 PostRouting 链的规则查看当前数据包的转发是否要做 SNAT,处理完成后发出数据包。 值得注意的是,当数据包流入后,经过路由选择发现不是发给 Local 的包,则会通过 FORWARD 链直接到达 POSTROUTING 链,而不会再走 OUTPUT 链。
数据流出
- 当数据包从本机准备发出时,会先经过 Nat 表的 output 链进行规则检查;
- 随后,会经过 Filter 表的 output 链进行规则检查;
- 最后根据 Nat 表中 PostRouting 链的规则查看当前数据包的发出是否要做 SNAT,处理完成后发出数据包。
完整图示
常用 iptables 命令使用
iptables 命令的大致语法如下,详细使用 参见 manual 手册:
|
|
基础篇
-
查看 iptables 命令使用方式
1 2 3 4# 查看 iptables 使用手册 man iptables # 查看 iptables 详细参数使用手册 man iptables-extensions -
查看 Filter 表中所有链以及规则
1iptables -nL --line-numbers-n:将主机信息(IP 地址,端口等)以数字的形式打印出来。默认会以 hostname 等方式打印出来; -L:显示规则链中已有的条目; –line-numbers:显示条目序号。
-
向 filter 表的 INPUT 链中新增拒绝所有来自 192.168.1.1 的数据包并指定其序号为 2
1iptables -I INPUT 2 -s 192.168.1.1/32 -j DROP-I:表示 insert,即向链中插入一条规则,INPUT 为链名,2 为规则的序号; -s: 代表匹配源地址; -j:规则目标(Target),DROP 代表丢弃所有包。
-
删除 filter 表的 INPUT 链中拒绝所有来自 192.168.1.1 的数据包的规则
1iptables -D INPUT -s 192.168.1.1/32-D:表示 delete,即从链中删除相关规则。
-
删除 filter 表的 INPUT 链中序号为 2 的规则
1iptables -D INPUT 2-D:表示 delete,即从链中删除相关规则,链名后面可以接数字,表示删除某个序号。序号怎么获取可以在查看链规则时使用 –line-numbers 选项。
-
向 filter 表的 INPUT 链中追加一条拒绝所有发送到 192.168.1.1 的数据包
1iptables -A INPUT -d 192.168.1.1/32 -j DROP-A:表示 append,即向链末尾追加一条规则; -d:代表匹配目的地址。
-
在 nat 表的 PREROUTING 链中新增一条序号为 1 的 LOG 规则
1 2# LOG 目标通常放在对数据包过滤和处理前,可以用来分析数据包流向。 iptables -I PREROUTING -t nat -j LOG --log-prefix "[NAT_PREROUTING_LOG]"-I:表示 insert,即向链中插入一条规则,PREROUTING 为链名,没有指定序号默认为 1,即顶部插入; -j:规则目标(Target),LOG 代表获取数据包并打印日志; –log-prefix:日志信息的前缀,只能在
-j LOG的情况下使用。可以通过man iptables-extensions查看其他针对某个 Target 的配置使用方式。 -
保存当前系统 iptables 规则
1iptables-save > $HOME/iptables-save.bak -
在 filter 表的 INPUT 链上对所有经过路由选择后判定为发给本机的数据包做跳转至 KUBE-NODE-PORT 链的操作
1iptables -I INPUT -m addrtype --dst-type LOCAL -j KUBE-NODE-PORT-m:表示 match,这里涉及到 iptables 扩展的用法,即 包匹配扩展模块(extended packet matching modules)。这里使用的 addrtype 意思是通过选项指定的地址类型进行匹配,结合 –dst-type 不难得知:当数据包的目的地址类型是本机时,则该包匹配该规则。
实战篇
-
禁止源地址 192.168.1.1 访问服务器的 22,53,80 端口:
1iptables -I INPUT -s 192.168.1.1/32 -p tcp --dport 22,53,80 -j DROP-s:source address,匹配源地址 -p:protocol,匹配协议 –dport:destination port,匹配目的端口。逗号分隔多个端口。
-
对于访问量比较大的服务器,例如 192.168.1.1,可以通过 raw 表配置绕过连接跟踪:
1iptables -t raw -A PREROUTING -d 192.168.1.1/32 -p tcp --dport 80 -j NOTRACK -
将访问 192.168.1.1:80 的请求转到 192.168.1.2:9000 上
1iptables -t nat -A PREROUTING -d 192.168.1.1 -t tcp --dport 80 -j DNAT --to-destination 192.168.1.2:9000 -
实现所有 192.168.1.0/24 的地址通过 123.123.123.123 公网地址访问公网
1iptables -t nat -A POSTROUTING -s 192.168.1.0/24 -j SNAT --to-source 123.123.123.123 -
拒绝一分钟内新建超过 4 次 SSH 连接的 IP 再次连接
1 2iptables -A INPUT -p tcp -m tcp --dport 22 -m state --state NEW -m recent --set --name SSH --rsource iptables -A INPUT -p tcp -m tcp --dport 22 -m state --state NEW -m recent --update --seconds 60 --hitcount 4 --name SSH --rsource -j DROP